Day 2735 按下Ctrl+Alt+Shift+V后出现Version对话框
同事发消息来求助,说是一按InDesign的原位粘贴快捷键Alt+Shift+Ctrl+V就冒出一个对话框,长这个样子:
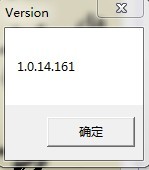
在接下来的排查中发现这个对话框有以下几个特点:
1、在许多程序中按下Ctrl+Alt+Shift+V都会蹦出来,但资源管理器等系统程序里不会;
2、关掉已知会抢占热键的程序(比如QQ等)并不能解决问题。
3、将InDesign这个原位粘贴快捷键更换为其它组合即恢复正常。
网上没有任何答案,一头雾水地到处搜索。考虑到很多程序里都会弹,估计热键被注册成全局了,但究竟哪个程序的Version是1.0.14.161呢?
Google把一堆IP查询网站的结果给了这串长得很像IP地址的数字,一开始以为什么都搜不到了,后来转了一大圈在最后一页找到这么一个俄文网站:
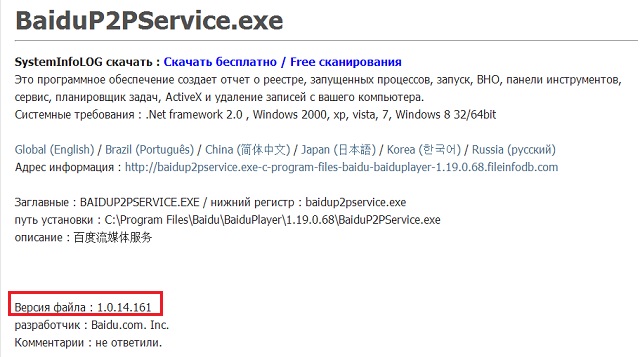
立马回头去问同事让他看任务管理器,果然有这个进程,Kill掉之后原位粘贴恢复正常,再找到百度影音的卸载项卸载,重启,再没发生。
百度你能不那么流氓不?你认为这么长的快捷键谁都按不到吗,还敢注册成全局热键……
我讨厌一些国产软件不是没有原因的。